Object Storage
Object Storage Summary
- Data is stored as objects in one large, scalable pool of storage
- Objects are stored with metadata – information about the object
- An Object ID is stored, to locate the data
- REST is the standard interface, simple commands used by applications
- Objects are immutable; edits are saved as a new object
Why Object Storage?
Massive Data Growth Depending on which analyst firm you talk to, you will hear storage growth predictions that vary between 30x-40x for the next decade. That means we will all be storing 30 to 40 times as much digital data ten years from now, compared to today. At the same time, companies will only invest an additional 50% in personnel to manage their storage infrastructures. This means that the average storage operator will have to manage 15-20 times as much storage a decade from now. This will drive the need for storage platforms that require little management effort and scale out to virtually unlimited capacities.
Always Online
Much of that data growth is driven by the recent innovations in cloud and mobile computing. We already mentioned Amazon S3, but there are also Google®, Facebook®, Apple® and several smaller public storage cloud offerings that set a new level of expectations where all data needs to be available anywhere at anytime.
Power to the Applications
File-based storage platforms not only fail to scale suffi ciently, they also become obsolete as more and more applications are designed to use REST API’s (the default interface for object storage platforms) to talk directly to the storage, without additional (fi le system) layers in between. This greatly simplifi es architectures and delivers signifi cant performance gains.
The Big Data Explosion
Essentially, there are three types of Big Data: Big Structured Data, Big Semi-structured Data (Big Data Analytics) and Big Unstructured Data. All three require one or more of the “three V’s”, the commonly accepted definition of Big Data: “Big Data refers to any set of data that comes in great Volumes, has a large Variety of information and/or is consumed at high Velocity.
Big Structured Data refers to large enterprise databases. Velocity is key here, hence the success of the super fast SSD drives. Big Semi-structured Data refers to massive volumes of small log files (often sensor information), that is collected for analytics. Therefore, we also talk about Big Data Analytics. This data is stored in distributed frameworks that support distributed processing. Think of Hadoop® and MapReduce. Object Storage is not commonly used for structured or semi-structured Big Data, unless it is for archival purposes.
The sweet spot for object storage is Big Unstructured Data, which refers to all data that users best understand as files. Think of image and movie data – always growing and always in higher resolution – music files, office documents etc. Analysts believe that 80% or more of the expected data growth will be unstructured data. File based storage platforms cannot support this growth. This is the problem Object Storage solves.
We All Use Object Storage Everyday
Possibly the largest object storage infrastructure, and one of the drivers for the adoption of object storage is Amazon’s S3. This “public” storage cloud service was launched in 2006 and has stimulated many application developers to have their applications use S3 as backend storage. The benefits were clear: no hassle with a private infrastructure, relatively low cost, pay as you go, scale as needed and a very simple interface.
However, while Amazon advertises very low cost to store data on their infrastructure, there are some hidden costs such as network traffic. At a certain volume of data, there is a point of cost inflection. Many of the startups that launched on Amazon over the past years and who clearly see the benefits of object storage, are now deploying their own infrastructure using object storage platforms.
Also, not everyone wants their data in a public environment with debatable SLA’s and moderate security at best. More and more enterprises are choosing to deploy their own internal storage clouds to facilitate cloud-based applications. These infrastructures need similar or better availability and durability than the available public services.
Use Cases
Object Storage is more than a smarter paradigm that allows you to store large volumes of unstructured data. Features like massive scalability, REST APIs, geographic distribution, enable a series of compelling use cases. An interesting side effect is that solutions tend to overlap. Dropbox® is not just file sharing, it’s backup, collaboration,archiving and mobile storage. Here are a few popular use cases:
Online Web Services: As we mentioned earlier, one of the drivers for object storage is the trend to use more and more online cloud applications. Previously, without Amazon’s S3, none of this would have been possible. The more successful web services companies are now gradually making the move to in-house infrastructures. Also, with corporate security policies, IP and compliance considerations, most enterprises prefer to run cloud applications on private storage infrastructures.
File Sharing is by far the most popular object storage use case. Dropbox offered a solution for a need that most of us did not know we had. Today, service providers are now deploying similar services and enterprises are deploying private file sharing services – as people utilize a variety of devices at home, at work and on-the-go. They collaborate with people across the office or around the world.
Cloud Backup is increasingly popular. There are dozens and dozens of online services for backup. For enterprises, the idea of backing up to low cost, highly scalable disk infrastructures - rather than tape, which can be cumbersome for recovery - is also very compelling
Cloud Archives: Data archiving decisions used to be very simple: data that was infrequently accessed was moved off disk to tape. Very few arguments could beat the low TCO of tape. Disk archives were hard to justify and reserved for those exceptional use cases where latency outweighed the huge cost of disk archives. With object storage, it is now possible to deploy disk archives at an acquisition cost and TCO close to that of tape. Many organizations are opting for hybrid environments - with a really, really superfast “hot” disk tier and a very cheap “cold” tape tier.
Worldwide Collaboration: Globally distributed teams have become standard practice. Think of researchers from different institutions working on the same project. Think of a movie being shot in New Zealand and produced in Los Angeles - or software being developed in California and then tested in India. Geographically distributed storage pools enable teams to work in real-time on the same datasets.
How Does Object Storage Work?
Issues with File Storage
As we explained earlier in this document, file based storage is a great concept: users can access the same resources through a corporate network. The file system takes care of permissions, access rights and avoids users overwriting each other’s data. File systems can even present data in a hierarchical “Directory” structure, which until now has been a very useful tool to keep data organized. The underlying software for such file systems contains a lot of “ingenuity”, which rapidly becomes “complexity” when scaling-out the infrastructure.
The concept of a “file” on a computer system is so well ingrained that it is often difficult to think of computer storage in different terms. It is clearly a very powerful and natural way to think of data. Object Storage is distinct from “file storage”, but in some ways is even a more natural and powerful way to organize data.
The “file” concept is an abstraction. In actuality, data in a computer system is stored in fixed size “blocks” which are “addressed” with a number – which ultimately is a physical location in a storage device. This is the case for data stored in a NAS, a SAN or when using Object Storage. The system presents those blocks to the user or application in a form that is useful. For non-transactional data, that form is usually a file.
File storage systems will also store a small amount of information that tells which of those data blocks make up the file, in which order, and finally what “name” has been applied to the collection of blocks. This additional “data about data” is called “file system metadata”. Keeping track of the file system metadata is the responsibility of the “file system”. To keep even more than a few files organized, a file system imposes a hierarchy on the metadata in the form of “directory structure”. A key concept of the file system is the notion that the files themselves have relationships to one another – as one could think of files being “co-located” in a directory.
When the system is instructed to “read a file”, the repository of file system metadata is consulted and the required data blocks are retrieved from the storage device. Writing data into a file system has the additional complexity of requiring that the file system metadata must be written or updated - potentially by several users or processes simultaneously. Numerous techniques and designs exist that attempt to minimize the impact of dealing with file system metadata, and the “locking” problem associated with simultaneous access. Unfortunately, as the number of files in the system grows large, keeping the file system metadata correctly organized (so that the names and the data blocks that make up files can be found) becomes increasingly complex. As this requirement increases, keeping track of billions of “files” (which may be distributed across a number of network connected computer systems), the abstraction of the “file system” begins to breakdown. Moreover, the hierarchical structure of the “file system” is insufficient to adequately categorize the data in the system.
File systems require at least three layers of software constructs to execute any file operation. As they allow files to be amended by multiple users, they must maintain complex lock structures with OPEN and CLOSE semantics. These lock structures must be distributed coherently to all of the servers used for access.
Also, as data is placed (based on random block availability), traditional file systems are always fragmented. This is especially true in environments where the data is unstructured and it is not uncommon to write widely varied file sizes. Using a traditional file system designed for amendable data, storing immutable data constitutes an inappropriate and wasteful use of bandwidth and compute resources. This highly inefficient approach requires a great deal of additional hardware and network resources to achieve data distribution goals. These systems now become exponentially more complex as they are scaled-out. Object storage systems dispense with the overburdened concept of file system metadata. This approach allows the system to separate the storage of data from the relationship that the individual data items have to each other. In an object storage system, the physical storage blocks are organized into “objects” which are collections of data blocks represented by an identifier. There is no “hierarchy” imposed on the data and no repository of the objects’ metadata to be consulted when reads or writes are requested. This approach allows an object storage system to scale with both the requirements and size of the system, well beyond the technical & practical boundaries of traditional file systems.
While Object Storage systems do not use file system metadata, they do employ object metadata (customizable information about the objects). This information can later be used to query or analyze the information stored. Object metadata for a photo could be the day it was taken, the last time it was modified, the type of camera that was used, whether a flash was used, where it was taken, etc. Object metadata will play an increasingly important role as we store more and more information, but it does not add complexity to the system like file system metadata does.
At the highest level, storage servers are, like NAS and SAN, simply boxes with a lot of disks in there. Typically, object storage vendors will use SATA disks in their systems, and may include SSDs for caching. Some platforms opt for separate controllers, but in essence that does not make a diff erence, as the storage is presented as one pool (namespace). When choosing an object storage platform, it’s important to understand the limitations of the namespace and how the system combines diff erent pools or namespaces. Manyvendors claim infi nite scalability, but there is no such thing. The important thing is to understand how namespaces are combined, presented and managed. How many such namespaces can be combined? Are they managed as one system? The system software manages most of that.
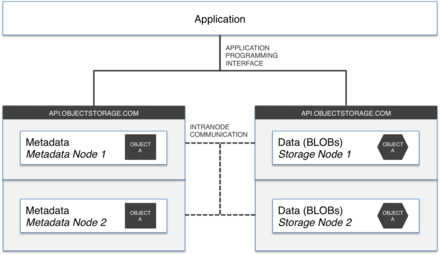
The actual software layer is where vendors can diff erentiate. The list of possible features is endless. A single management interface is always great. Self-healing capabilities are a must for environments that will scale into the hundreds of petabytes. The software layer also provides data protection mechanisms, which we will cover in the next section.An Object ID is stored, to locate the data
The standard interface to access data in an object storage platform is a RESTful interface or REST API. This is a set of simple commands that application developers use in their code to let the application access the data. The basic REST commands are LIST, GET, PUT and DELETE, which are used to list (a selection of) objects, read an object, store an object or delete it. There is no standard for REST yet, but the so called Amazon API is by far the most popular amongst developers. Hence, most object storage providers will provide an “Amazon compatible API”, which is typically a subset of the commands that are supported by Amazon S3. As most legacy applications were designed to interface with a file system, most object storage platforms will also provide one or more file interfaces (a fi le system layer on top of the object storage pool – also called a file system gateway) and often a selection of programming language-specific API’s will be provided as well. DDN’s WOS has the widest selection of interfaces on the market.
Data Protection: Erasure Coding or Not?
Several data protection mechanisms are used for object storage. The one method that is being abandoned, however, is RAID (which has been the defacto data protection scheme for SAN and NAS for the past two decades). The problem with RAID is that it was originally designed for small capacity disks . The larger the drive capacity, the longer it takes to restore a failed drive. During this restore, the data is less protected. If you are on RAID 5, and a second disk fails in your RAID group during the lengthy restore, then data loss will occur. Also, as all processing capacity is used for the restore, users will experience severe performance drops as data is being written to the replacement disk. Large systems with hundreds of TBs or Petabytes, will routinely be in constant rebuild mode, as drives routinely fail. In an effort to shorten these longer rebuild cycles, RAID systems ship with faster processors, which also consume more energy, but this only masks the problem at best.
The simplest way to protect data is to make several copies, replication. A popular concept is called “three copies in the cloud”, promoted mostly by public cloud platforms like Amazon S3 and Rackspace®. While three copies in the cloud provides acceptable data protection, it is also very lucrative for the cloud provider as they are in the business of selling more storage capacity. Swift™, the object storage component of Rackspace’s open source cloud infrastructure also uses pure replication.
A more efficient data protection mechanism is erasure coding. Today, there are several flavors of erasure coding, each one with its own benefits. Erasure coding’s key advantage is that you can break up your data into n fragments, add m additional fragments, store the fragments across n+m devices, and then recover the original data from any n of the devices. Survive 4 failures? 10? Pick a number! Also when a disk is lost, the system only has to calculate new fragments, to be spread over any selection of disks with available capacity. This is a lot faster and more efficient than restoring an entire RAID-based disk, even if it was only 20% full.
Erasure coding can be implemented locally or distributed, which means that fragments are spread over multiple data centers (at least three) and the system can survive failure of a full datacenter. Distributed erasure coding drastically reduces the overhead (the extra storage that is needed to protect the data). Five 9’s or more are guaranteed with overhead numbers as low as 20% - as opposed to 3 copies requiring 200% overhead. The problem with distributed erasure coding is that it creates a huge WAN cost, as rebuilds require data transfer between the datacenters. Also, the availability highly depends on the WAN connectivity. Each data read from a distributed erasure coding pool, requires data to be read from three data centers. If any of these connections have high latency, the user will notice the delayed response.
An interesting, “best of both worlds” solution is local erasure coding with replication. Such architecture combines the benefits of erasure coding with those of replication (a full copy is present in each datacenter). While such a setup requires more overhead than the distributed alternative, the TCO is typically a lot lower due to the reduced WAN traffic.